
Paper study - Attention Is All You Need
by 한지상
Transformer
Conference: Neurpis2017
Presenter: 한지상
Title: Attention Is All You Need
URL: https://papers.nips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
Abstract
- 주된 sequence transduction models는 encoder와 decoder을 포함한 복잡한 recurrent 또는 convolutional neural network에 기반한다.
Transformer - attention mechanism 에만 기반.
- 이 모델은 WMT 2014 영어→독일어 번역 task에서 이전보다 2 높은 28.4 BLEU를 달성하였다. 여기서 이 모델은 8개의 GPU로 8일 동안 학습시켜 41.8점의 BLEU state-of-the-art 단일 모델이다.
이 논문에서 Transformer는 크거나 한정된 학습 데이터를 가지고서도 성공적으로 다른 task들에 일반화될 수 있음을 보인다.
1. Introduction
RNN, LSTM, GRU는 sequence 모델링 문제에서 뛰어난 성과를 보이며 확고히 자리를 잡았다.
하지만 recurrent모델은
- 학습되는 문장이 길어질수록 서로 멀리 떨어진 문장에 대한 정보가 줄어들어 제대로된 예측을 할 수 없다. → Long-term dependency problem
- 순차적인 연산으로 병렬화가 불가능하여 연산속도가 저하된다.
→ Recurrent모델의 제약사항들을 피하고 입출력 사이에 전역 의존성을 이끌어내기 위해 Transformer을 제안한다. (병렬화가 가능하다.)
2. Background
3. Model Architecture
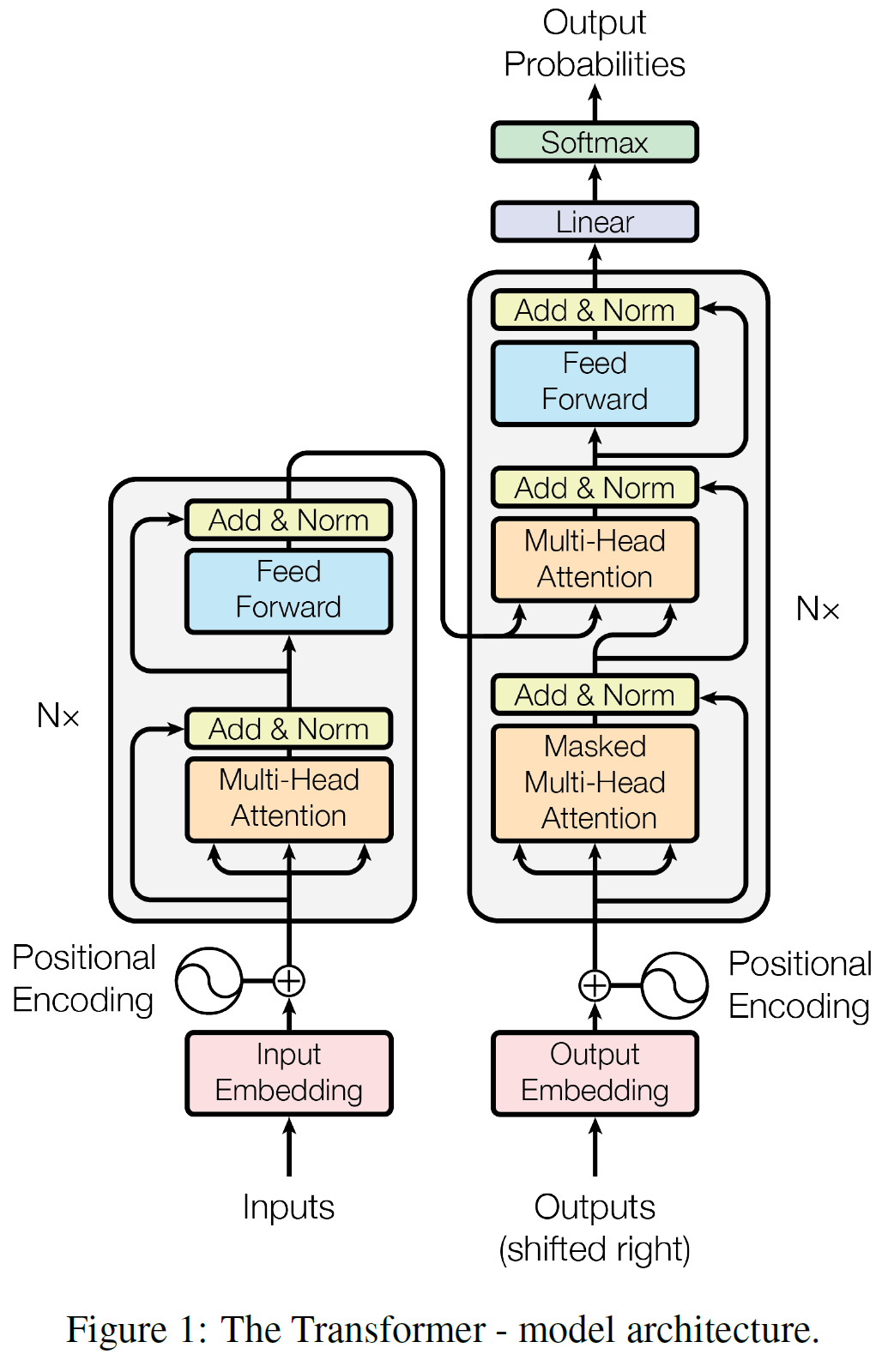
Transformer - encoder / decoder
- encoder - symbol representations (입력)$(x_1, … , x_n)$ 을 continuous representations $z=(z_1, … , z_n)$으로 매핑한다.
- decoder - z가 주어지면, 디코더는 한번에 한 원소씩 출력 sequence $(y_1, … , y_n)$를 생성한다.
- 각 단계는 auto-regressive (자동회귀)이며, 다음 단계의 symbol을 생성할 때 이전 단계에서 생성된 symbol을 추가 입력으로 받는다.
Encoder
- N = 6개의 동일한 layer로 구성된다. 처음 input이 첫 번째 layer에 들어가고 다음 layer은 이전 layer의 결과값이 들어간다. $layer(x)$가 다시 $layer$에 들어감.
- 각 layer은 multi-head self-attention mechanism 과 simple, position-wise fully connected feed-forward network 로 구성된다.
- 각 sub-layer의 출력값 - $LayerNorm(x+Sublayer(x))$
- $Sublayer(x)$는 sub-layer 자체로 구현되는 함수이다.
- 이러한 residual connection을 용이하게 하기 위해 embedding layer을 포함한 모든 sub-layer은 $d_{model}=512$ 차원의 출력값을 가진다.
Decoder
- N = 6개의 동일한 layer로 구성된다.
- sub-layer는 Encoder의 것과 동일하지만 Encoder stack의 출력값에 multi-head attention을 수행하는 sub-layer을 더 가진다.
- Decoder가 출력을 생성할 때 다음 출력에서 정보를 얻는 것을 방지하기 위해 masking을 사용한다. (치팅방지 🤥)
3.2 Attention
Attention함수는 query + key-value -> output 으로의 변환을 수행한다.
query, key-value, output: 벡터
output은 value들의 가중합으로 계산되며, 가중치는 query와 연관된 key의 호환성 함수(compatibility function)에 의해 계산된다.
3.2.1 Scaled Dot-Product Attention

- Input - $d_k$차원의 query와 key, $d_v$차원의 value

query와 모든 key의 dot-product를 계산하고, 각각 $\sqrt{d_k}$로 나누고(scaling), value의 가중치를 얻기 위해 softmax함수를 적용한다.
→ query와 유사한 value일수록, 더 높은 값을 가짐. Attention
query들에 대해 동시에 계산하기 위해 이들을 행렬 Q로 묶는다. key - K, value - V
Q: 디코더의 이전 layer hidden state
K: 인코더의 output state
V: 인코더의 output state
3.2.2 Multi-Head Attention

$d_{model}$차원의 query, key, value로 단일 attention function을 사용하는 것보다 이들을 각각 $d_k, d_k, d_v$차원으로 각각 다르게 $h$번 학습시키는 것이 낫다.
→ 각 sub-layer에 동일한 부분이 h개 존재한다는 뜻.
각각 계산된 $h$쌍의 $d_v$차원의 출력을 concatenate한 후 선형함수에 통과시켜 최종 출력값을 계산한다.


논문에서는 $h=8, d_k=d_v=d_{model}/h=64$를 사용하였다.
3.2.3 Applications of Attention in out Model
- encoder-decoder Attention layer에서 query는 이전디코더의 layer에서, key와 value는 인코더의 출력에서 온다. → 디코더가 입력의 모든 위치(원소)를 고려할 수 있도록 한다.
- 인코더는 self-attention layer을 포함한다. → 인코더의 각 원소는 이전 layer의 모든 원소를 고려할 수 있다.
- 디코더에서는 masking을 통해 미래시점의 단어들을 미리 조회함에 따라 현재단어 결정에 미칠 수 있는 영향을 막는다. 이를 위해 i번째 position에 대한 attention을 얻을 때 , i번째 이후에 있는 모든 position은 Attention식에서 softmax의 input값을 $-inf$에 가까운 매우 작은 수로 설정한다. → i번째 이후에 있는 position에 attention을 주는 경우가 없겠죵
3.3 Position-wise Feed-Forward Networks
$FFN(x)=max(0,xW_1+b_1)W_2+b_2$
Linear Transformation → ReLU → Linear Transformation 로 이루어져있다.
3.5 Positional Encoding
Transformer에서는 recurrence와 convolution을 사용하지 않기때문에 단어의 sequence를 이용하기 위해서는 단어의 position에 대한 정보가 필요하다.
→ 인코더와 디코더의 input embedding에 positional encoding을 더해준다.
- positional encoding은 $d_{model}$(embedding)과 같은 차원을 갖는다.
모델에서는 sin, cos함수를 사용하였다.

-
pos: position i: dimension 주기: $10000^{2i/d_{model}}2\pi$ - pos - sequence에서 단어의 위치, 해당 단어는 $i : 0 -> d_{model}/2$
5. Training
- Optimizer
Adam optimizer에서 learning rate를 고정시키지 않고 변화시킴.

warmup_step까지는 선형적으로 증가하다가 이후에는 step_num의 inverse square root에 비례하도록 감소시킨다.
처음에는 학습이 잘 되지 않은 상태이므로 learning rate를 빠르게 증가시켜 변화를 크게 주다가 학습이 어느정도 될 때, 변화를 작게 주기 위함.
6. Results



7. Conclusion
encoder와 decoder에서 attention을 통해 query와 가장 밀접한 연관성을 가지는 value를 강조할 수 있고 병렬화가 가능하당…
Subscribe via RSS
{kind=link}